○研修評価のハンドブック。抜き書きのみ。Kindleのメモとエクスポート機能に助けられました。この本は、読み切るのに、3か月ぐらいかかりました。様々な評価手法の紹介と、実践的な助言が参考になります。
HANDBOOK OF PRACTICAL PROGRAM EVALUATION:4th Edition
(ESSENTIAL TEXTS FOR NONPROFIT AND PUBLIC LEADERSHIP AND MANAGEMENT)
Kathryn E. Newcomer、 Harry P. Hatry、 Joseph S. Wholey (2015)
●Preface
those in the consulting world—both individuals new to evaluation and experienced evaluators (who may find new ideas to add to their current toolkit).
◎PART ONE Evaluaton Planning and Design
●CHAPTER ONE Planning and Designing Useful Evaluations
a program is a set of resources and activities directed toward one or more common goals
Program evaluation is the application of systematic methods to address questions about program operations and results. It may include ongoing monitoring of a program as well as one-shot studies of program processes or program impact. The approaches used are based on social science research methodologies and professional standards.
practical program evaluation
Five basic questions should be asked when any program is being considered for evaluation or monitoring
Figure 1.1 displays six important continua on which evaluation approaches differ.

Traditional social science research methods have called for objective, neutral, and detached observers to measure the results of experiments and studies.
Evaluators make judgments about the value, or worth, of programs (Scriven, 1980).
qualitative research approach or mind-set means taking an inductive and open-ended approach in research and broadening questions
The most common sources of quantitative data are administrative records and structured surveys”
Mixed-method approaches in evaluation are very common
randomized controlled trials (RCTs) are the “gold standard” for evaluation
The key question facing evaluators is what type and how much evidence will be sufficient?
It is usually difficult to establish causal links between program interventions and behavioral change.
Choose Appropriate Measures
The validity or authenticity of measurement is concerned with the accuracy of measurement,
so that the measure accurately assesses what the evaluator intends to evaluate.
For quantitative data, reliability refers to the extent to which a measure can be expected to
produce similar results on repeated observations of the same condition or event.
For qualitative data, the relevant criterion is the auditability of measurement procedures.
Internal validity is concerned with the ability to determine whether a program or intervention has
produced an outcome and to determine the magnitude of that effect.
There are several challenges in capturing the net impacts of a program, because other events and processes are occurring that affect achievement of desired outcomes.
For qualitative data, the transferability of findings from one site to another (or the
future) may present different, or additional, challenges.
difficult trade-off decisions as the evaluator attempts to balance the feasibility and cost of
alternative evaluation designs against the likely benefits of the resulting evaluation work.
The goal of conducting any evaluation work is certainly to make positive change.
Evaluation effectiveness may be enhanced by efficiency and the use of practical, low-cost
evaluation approaches that encourage the evaluation clients (the management and staff of the program) to accept the findings and use them to improve their services.
●CHAPTER TWO Analyzing and Engaging Stakeholders
stakeholders as individuals, groups, or organizations that can affect or are affected by an
evaluation process or its findings.
primary intended user as a subset of key stakeholders.
People skill are critical.
six is the median number of primary intended users typically involved directly in an evaluation
project
strategically locate people who are committed, competent, and connected—in short, who are tipping point connectors, people who are looked to by others for information
power and status differences exist among stakeholders.
Four categories of stakeholders
1.Players—people with both an interest and significant power.
2.Subjects—people with an interest but little power.
3.Context setters—people with power but little direct interest.
4.The crowd—people with little interest or power.
●CHAPTER THREE Using Logic Models
The logic model also helps evaluators frame evaluation reports so that findings from the
evaluation and measurement can tell a performance “story” and results
can be linked to program elements and assumptions about them.
A logic model is a plausible and sensible model of how a program will work under certain environmental conditions to solve identified problems (Bickman, 1987).
Figure 3.1 Basic Logic Model.
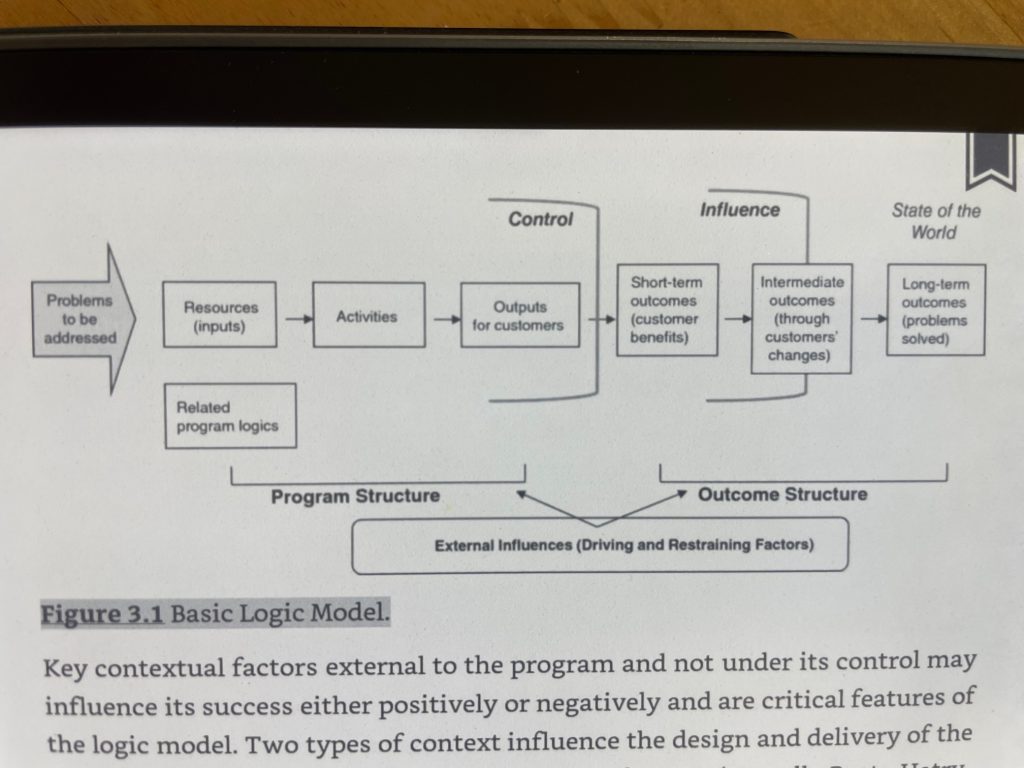
The process of developing a logic model brings people together to build a shared understanding of
the program and program performance standards.
logic model is constructed in five stages
The logic model describes the logical linkages among program resources, activities, outputs for
customers reached, and short-term, intermediate, and long-term outcomes.
●CHAPTER FOUR Exploratory Evaluation
evaluators often find it difficult to determine the appropriate focus for their work
first to conduct a rapid, low-cost exploratory evaluation
Evaluability assessment (EA)
Rapid feedback evaluation (RFE)
EA and RFE are the first two steps in a sequential purchase of information process in which
resources are invested in further evaluation
RFE provides policymakers, managers, and other stakeholders with two products
Evaluation synthesis summarizes what has been learned about program effectiveness through a
systematic review of all relevant prior research and evaluation studies.
Either evaluation synthesis or evaluability assessment may provide a good starting point
●CHAPTER FIVE Performance Measurement Monitoring Program Outcomes
performance measurement is a fundamentally different enterprise from program evaluation
on the grounds that they serve different purposes, and that while program
evaluation encompasses a set of tools used by evaluators, performance
measurement is used principally by managers
good measurement is high degree of validity, the degree to which an indicator accurately
represents what is intended to be measured, and reliability, which concerns
consistency in data collection.
external benchmarking, comparing their own performance data against the same measures for other
similar agencies or programs.
use a variety of display formats (dashboards, spreadsheets, graphs, pictures, and maps) to
present performance data clearly.
●CHAPTER SIX Comparison Group Designs
The purpose of most impact evaluations is to isolate the effects of a program to help officials and
citizens decide whether the program should be continued, improved, or expanded to other areas.”
What would have happened in the absence of the program?”
comparison group distinguishes an untreated but not randomly assigned group from a randomly
assigned control group used in randomized experiments.
all designs for impact valuations that do not involve random assignment to treatment and control as
comparison group designs.
randomized experiments are not the ideal
Under certain circumstances, however, comparison group designs can produce accurate estimates of
program impact
In the world of practical program evaluations, random assignment is always difficult and
frequently impossible.
Often, comparison group designs are the only practical means available for evaluators
8 alternative comparison group designs;
1.Naïve Design: naturally occuring treated and untreated groups.
2.Basic Value Added Design
3.Regression-Adjusted Covariate Design
4.Value-Added Design Adjusted for Additional Covariates
5.Interrupted Time Series Designs
6.Fixed-Effect Designs for Longitudinal Evaluations
7.Matching Designs
8.Regression Discontinuity Designs
reduce bias in the estimates of program impacts.
●CHAPTER SEVEN Randomized Controlled Trials
the gold-standard method in evaluation research.
efficacy evaluation
effectiveness evaluation
Fisher in an agricultural context (Fisher, 1971). This research method was adopted for use
with humans by education researchers in the 1930s
the use of RCTs in medical research has exploded, and now no new pharmaceutical product will be
licensed until it has been tested in several large RCTs with human participants.
Although, in theory, random allocation ensures comparable groups at baseline, bias can be
introduced at any stage, including initial randomization.
huge potential for contamination of the control participants with the treatment condition.
One approach is the participant preference design—also known as the Brewin-Bradley approach.
participants are asked about their preferences before randomization
the waiting list design (where participants are informed that they will receive the
intervention at a later date), and the stepped wedge design.
A special form of the waiting list design is known as the stepped wedge, or multiple baseline,
method.
Most trials evaluating policy interventions use cluster randomization.
As a rule of thumb ICC values are generally between 0.01 and 0.02 for human studies
social science trials are different from medical experiments. Health care trials—specifically pharmaceutical trials—are more likely to transfer beyond their experimental population than education trials
significant numbers of RCTs do not use an independent, blinded follow-up or ITT analysis
Although this renewed interest is welcome, it is necessary to ensure that trials are conducted
to the highest standard
●CHAPTER EIGHT Conducting Case Studies
case studies are the preferred strategy when how or why questions are asked.
The goal of this type of study is to develop a comprehensive understanding of a case, or complex
bounded system, including the context and circumstances in which it occurs,through extensive description and analysis (Smith, 1978).
Case studies generally all into one of three categories: exploratory, descriptive, or explanatory.
A common pitfall in case study research is collecting too much information,
A key decision in designing case studies is selecting the unit of analysis.
single-case designs are appropriate when the case represents a “critical” test of exis
ing theory, a rare and unique circumstance, or when the case serves a revelatory purpose.
Multiple-case designs are used to provide descriptions and make comparisons across cases to
provide insight into an issue.
Because data collection is nonroutinized, interviewers should be able to discern what is important from what is not.
The hallmark of a case study is an in-depth portrait of the case.
The richness and complexity of the data collected in case studies distinguishes them from many other forms of qualitative research.
The first common pitfall is that case studies are unlikely to be representative, and thus
generalizing the findings is often problematic.
●CHAPTER NINE Recruitment and Retention of Study Participants
Recruitment for evaluation purposes means obtaining the right number of program participants
with the appropriate eligibility characteristics to take part as members of the needed comparison groups.
Retention, for evaluation purposes, means maximizing the number of participants who continue the
intervention throughout the evaluation period and who are willing to provide follow-up information to the evaluators, often at a time after services for these participants have ended.
Planning for recruitment and retention is best done early.
most evaluators typically overestimate their ability to recruit and retain participants and spend
too little time on this aspect of their evaluation in the design phase.
Evaluation teams should take the approach of hoping for the best but planning for the worst.
Table 9.2 lists reasons for refusals and approaches to counteract them.
their “hidden” reason may be one of those listed in Table 9.2
●CHAPTER TEN Designing, Managing, and Analyzing Multisite Evaluations
●CHAPTER ELEVEN Evaluating Community Change Programs
●CHAPTER TWELVE Culturally Responsive Evaluation Theory, Practice, and Future Implications*
CRE is a holistic framework for centering evaluation in culture (Frierson, Hood, Hughes, and
Thomas, 2010).
===
◎PART TWO Practical Data Collection Procedures
controversial topic, the use of stories in evaluation. He stresses the power of reporting stories,but makes no claim that these stories should replace quantitative data.
Cost is an important consideration in all data collection procedures.
Another key issue for data collection is quality control.
●CHAPTER THIRTEEN Using Agency Records*
Agency records will likely be a major source of important data for many, if not most,
evaluations.
Inevitably, evaluator will find less than perfect data from agency records.
●CHAPTER FOURTEEN Using Surveys
Even with the increasing number of e-mail and web surveys, traditional mail surveys are still a
popular form of data collection.
Considerations for the “No Opinion” or “Don’t Know”option
Studies have shown that including these items does not improve the consistency of respondents’
attitudes over time.
●CHAPTER FIFTEEN Role Playing*
Role playing is a research methodology used to directly observe a transaction.
Role playing as a research methodology developed from participant-observer methods used by
anthropologists (Erstad, 1998).
Because evaluation studies aim to generate results that can be aggregated across many tests,
data collection forms require predefined, closed-ended responses that can be consistently compared across tests.
One of the most important steps in implementing a successful role-play study is the meticulous
recruitment, selection, and training of role players.
the most successful candidates for any study will possess the ability to (1) maintain
confidentiality about their roles and the study as a whole; (2) remain objective about the subject matter and the individuals being studied; and (3) be credible in each and every portrayal.
Role playing can be used to study a variety of transactions in a natural manner that provides
researchers relatively unbiased data.
Role-playing studies that are well designed and implemented can produce results that are easily
understood by the public, trusted by policymakers, and useful to program evaluators.
●CHAPTER SIXTEEN Using Ratings by Trained Observers
These methods can range from a simple two-point, yes/no or present/not present rating to grading
(A, B, C, and so on) to other more complex scales.
Scorecard Cleanliness program has been described by Harry Hatry, a pioneer in the field of
performance measurement and trained observation, as “probably the longest running trained observer operation in the world” (Hatry, 2006, p. 100)
Trained observer ratings can serve to rigorously compare and assess differences in service quality and conditions over time or provide an accurate picture on a one-time or ad
hoc basis.
●CHAPTER SEVENTEEN Collecting Data in the Field
At least two types of fieldwork studies are common: program management projects and program
evaluation.
Standard social science principles (such as validity, reliability, and objectivity) must be
considered in developing the fieldwork plan.
fieldwork is conducted for at least two purposes:
To describe what happens at the level being examined (local office, local program, local agency, local community, state office, state agency, and so on) by collecting information about procedures and data on activities, services, institutional features, outcomes.
To explain why the situations are as they are.
one of the greatest pitfalls in conducting field-based studies is the risk associated with
collecting too much information
●CHAPTER EIGHTEEN Using the Internet
how the Internet can be used in three ways: to conduct electronic literature reviews, to
administer online surveys, and to post research.
One extraordinary gold mine is The Campbell Collaboration (campbell collaboration.org), which
regularly assembles updated, systematic reviews (essentially meta-analyses)
of studies of the impact of interventions and policy trials in the fields of
education, social welfare, psychology, and criminal justice, plus some
coverage of a few related areas.
the big-name search engines do not search the so-called “gray literature”
One recent study (Howland, Wright, Boughan, and Roberts, 2009, published in College and
Research Libraries journal, of all places) concluded that Google Scholar was
actually superior to the leading complex, proprietary library search
engines.
blurry boundary line among advocacy groups, consulting firms, and think tanks as well as to
their sheer number.
As of mid-2014, the leading online survey company was SurveyMonkey (surveymonkey.com), ranking
in the top (most accessed) 1,000 websites worldwide according to the Alexa
ranking of web traffic, far surpassing its competitors.”
●CHAPTER NINTEEN Conducting Semi-Structured Interviews
Curiously, this methodology does not have a consensus name.
“the semi-structured interview.”
Conducted conversationally with one respondent at a time, the SSI employs a blend of closed- and
open-ended questions, often accompanied by follow-up why or how questions.
About one hour is considered a reasonable maximum length for SSIs in order to minimize
fatigue for both interviewer and respondent.
Interviewers should establish a positive first impression.
Probably the best balance is to appear generally knowledgeable, in a humble, open-minded way, but
not to pose as more expert than the respondent (Leech, 2002).
●CHAPTER TWENTY Focus Group Interviewing
A focus group is a planned discussion led by a moderator who guides a small group of participants
through a set of carefully sequenced (focused) questions in a permissive and nonthreatening conversation.
the core features that make focus groups distinctive;
1.The Questions Are Focused
2.There Is No Push for Agreement or Consensus
3.The Environment Is Permissive and Nonthreatening
4.The Participants are Homogeneous
5.The Group Size Is Reasonable
6.Patterns and Trends Are Examined Across Groups
7.The Group Is Guided by a Skillful Moderator
●CHAPTER TWENTY-ONE Using Stories in Evaluation
Reporters and columnists consistently use stories about individuals to explain the latest research findings. The writers who best translate research findings use stories.
Quantitative data have never once led me to shed a tear or spend a sleepless night. Numbers may
appeal to my head, but they don’t grab my heart.
Stories help us interpret quantitative data. Stories can also be used to amplify and communicate
quantitative data.
Evidence suggests that people have an easier time remembering a story than recalling numerical
data. The story is sticky, but numbers quickly fade away.
Stories help communicate emotions. Statistical and survey data tend to dwell on the cold hard
facts.
An evaluation story is a brief narrative account of someone’s experience with a program,
event, or activity that is collected using sound research methods.
Robert Brinkerhoff, in his book Telling Training’s Story (2006), suggests beginning with a
survey and using the survey to identify stories of success.
Brinkerhoff indicates that training almost never helps 100 percent of the participants to be
successful. The survey gives the evaluator an idea of the percentage of success, and the stories describe the nature of the success.
better way to tell success stories is to make the client or customer the hero.
use stories to motivate or change behavior. Stories influence people.
Individual and small-group interviews are often the primary methods.
Evaluators need to be mindful of common questions asked about stories, such as: “Is this story typical?” or “How often do stories like this occur?”
certain strategies that make their stories effective.
eight elements;
- Stories Are About Person, Not an Organization
- Stories Have a Hero an Obstacle, a Struggle, and a Resolution
- Set the Stage for the Story
- The Story Unfolds
- Emotion Are Described
- Dialogue Adds Richness
- Suspense and Surprise Add Interest
- Key Message Is Revealed
The use of stories in evaluation studies offers considerable potential. Stories are memorable
and convey emotions. People have a natural interest in stories.
===
◎PART THREE Data Analysis
●CHAPTER TWENTY-TWO Qualitative Data Analysis
For example, although it may be useful to incorporate a count of how many young people in a
mentoring program gained new skills, a more comprehensive understanding of
the program is achieved from paying attention to how the young people
describe their experience of learning new skills, and the way they connect
their participation in the program with these outcomes.
Enumerative methods focus on categorizing qualitative materials so that they can be
analyzed quantitatively.
Enumeration is not recommended when the data is rich or detailed, as it tends to be overly
reductionist and can decontextualize or distort the meaning.
Classic content analysis is an example of an enumerative method of analysis, often used to analyze existing textual material such as newspaper reports or social media.
Enumerative methods are appropriate when the purpose of the analysis is to understand
frequency.
Descriptive methods of analysis focus on summarizing the information into a form that can then be
compared and contrasted.
common analytic choice often associated with descriptive methods in evaluation is matrix
displays.
common type of anaysis associated with hermeneutic methods is thematic analysis.
Explanatory methods of analysis focus on generating and testing causal claims from data and are
particularly relevant to address outcome evaluation questions.
Most evaluation clients want to understand the contribution of projects to the larger
program of effort, or they seek transferable lessons from implementation of
projects in an array of contexts.
These are causal or explanatory questions. They require analysis that can link proposed
causal mechanisms to specific outcomes.
Qualitative comparative analysis (QCA) is a systematic comparative approach that maintains a focus on the richness and context of cases.
determining causal claims in small n studies. Between five to fifty cases or more are appropriate
for QCA.
We have presented a typology of four purposes of qualitative data analysis and focused in on one
method that is closely associated with the purpose, enumerative, descriptive, hermeneutic, and explanatory.
The five high-level evaluation standards—utility, accuracy, feasibility, propriety, a
d accountability—provide a useful reference point for thinking about the quality of qualitative data analysis.
●CHAPTER TWENTY-THREE Using Statistics in Evaluation
In 1946, Stevens identified four levels of measurement: nominal, ordinal, interval, and
ratio. These levels have been used to describe empirical data ever since.
two types of descriptive statistics: those intended to summarize information on a single variable
(univariate statistics) and those intended to describe the relationship between two variables (bivariate statistics).
Nominal variables are most easily summarized by frequency counts and percentages.
program evaluation, basic question is whether participating in the program (the first variable)
had the intended effect on the outcome of interest (the second variable).
two most commonly used measures in program evaluation: the difference between two percentages
and the difference between two means
When the null hypothesis is rejected (using the 95 percent decision rule), it is appropriate to
state that the relationship in the sample data is “statistically significant at a confidence level of 95 percent.
the relationship found in the sample reflects a real relationship in the population from which
the sample was drawn.
The first is the chi-square test, a test that is used to test for relationships between nominal-
and ordinal-level variables.
The second most commonly used hypothesis test is the t test, which allows researchers to
test for the difference between two means.
Regression anaysis is used to describe relationships, test theories, and make predictions
with data from experimental or observational studies, linear or nonlinear
relationships, and continuous or categorical predictors.
variable that takes o values of only 0 or 1 is called a dummy or indicator variable.
The terms significance and statistical significance are conventionally reserved for the judgment
that sample results showing a relationship between variables can be generalized to the population from which the sample was drawn.
Factor analysis is the technique most frequently used for such data-reduction purposes.
reports for high-level officials, such as mayors and legislators, present a special case.
only findings that are of practical importance should be presented.
For a high-level audience, graphic presentations showing trends are typically preferable to
tables filled with numbers.
●CHAPTER TWENTY-FOUR Cost-Effectiveness and Cost-Benefit Analysis
Both cost-benefit analysis (CBA) and cost-effectiveness analysis (CEA) are useful tools for
program evaluation. Cost-effectiveness analysis is a technique that relates
the costs of a program to its key outcomes or benefits. Cost-benefit
analysis takes that process one step further, attempting to compare costs
with the dollar value of all (or most) of a program’s many benefits.
Indeed, both technique may be more of an art than a science.
●CHAPTER TWENTY-FIVE Meta-Analyses, Systematic Reviews, and Evaluation Syntheses
The selective reader could cite any single study—or selective number of studies—as “evi
ence” for a position
An effect size in any science is estimated relative to some basis for comparison, reference,
or benchmark.
The purpose of systematic review, meta-analysis, and evaluation synthesis is to reach
conclusions based on a summary of results from an assembly of studies.
The Best Evidence Encyclopedia (www.bestevidence.org) is a U.S.- and U.K.-based effort that
uses some of the basic evidence standards for identifying dependable studies.
===
◎PART FOUR Use of Evaluation
●CHAPTER TWENTY SIX Pitfalls in Evaluations
Two key issues in program evaluation are determining what the effects (outcomes) of the program
have been over a specific period of time and determining the extent to which
the specific program, rather than other factors, has caused those effects.
Both issues are typically subject to considerable uncertainty, particularly
given that the great majority of evaluations are not conducted under
controlled laboratory conditions.
Recognizing pitfalls should not be considered a weakness but rather a strength of rigorous
evaluation work.
●CHAPTER TWENTY SEVEN Providing Recommendations, Suggestions, and Options for Improvement
The difference between recommendations and suggestions is that the former sounds more
authoritative, compulsory, and imposing.
the evaluator may want to offer suggestions for improvement. This term connotes something
like, “I hope these ideas are helpful.
The key difference is how open the evaluation team is to the ideas that come pouring in—that is, encouraging and welcoming these ideas or being possessive and defensive about the recommendations that the team ultimately makes.
It makes perfect sense to include recommendations offered by others.
Take responsibility for the recommendations offered by the evaluation team.
●CHAPTER TWENTY-EIGHT Writing for Impact
Effective writing involves an interplay and command of three facets of communication:
The message: what the writer wants people to remember after they have read the report
The audience: individuals the writer wants to read or hear about the study
The medium: the many factors that carry the message—words, page, reports, typeface, graphics, paper, ink, color, computer screens, slides, newsletters, panel discussions, and the like
No report will matter much unless it passes what I call the Mom Test.
is because there is no message. The author may have provided lots of findings and good
recommendations, but no kernel, no unforgettable nub that attracts attention
and compels the reader’s interest.
The reaction that evaluators want to obtain from other stakeholders is: “Thanks. This was helpful.”
The killer paragraph is a lot more, too. It is the abstract that appears first in the version of
the report that is published in a professional journal.
The killer paragraph may be the only thing that most people will ever know about all that work
the team accomplished.
●CHAPTER TWENTY-NINE Contracting for Evaluation Products and Services
The practical advice in this chapter focuses on five areas:
1.Creating a feasible, agreed-on concept plan
2.Developing a well-defined request for proposal (RFP)
3.Selecting a well-qualified evaluator that fulfills the intent of the RFP
4.Constructively monitoring interim progress
5.Ensuring product quality
release of the RFP into the evaluation marketplace initiates the competition.
Nevertheless, successful evaluation contracting ultimately depends on the collective technical
competencies and communication skills of both contractor and sponsor staffs.
●CHAPTER THIRTY Use of Evaluation in Government The Politics of Evaluation
Global, national, and local forces demand higher levels of transparency, performance, and
accountability, and public trust in government remains low.
Evaluation is used in government to increase transparency, strengthen accountability, and
improve performance—all terms in good political currency
Four approaches can be used to help overcome political and bureaucratic challenges affecting the
use of evaluation:
(1) redesigning agency management systems to focus on results;
(2) creating incentives for higher program performance;
(3) developing key national, state, or community indicators; and
(4) creating performance partnerships.
●CHAPTER THIRTY-ONE Evaluation Challenges, Issues, and Trends
four challenges:
(1)quality control of the evaluation process;
(2) selection and training of evaluators;
(3) standards and ethics in evaluation work; and
(4) getting others to use evaluation findings to improve programs.
six trends in program evaluation likely to continue into the next decade.
1.Information Technology”
2.Big Data
3.Data Visualization
4.Complex Adaptive Systems
5.Evaluation Mandates
6.Demand for Rigorous Evidence
two primary reason for evaluation activities: to achieve greater accountability in the use of
public or donated funds and to help agency officials improve the effectiveness of their programs.
===
コメントフォーム